What is an accumulator in an accelerator’s GEMM engine and why does it matter?
GPUs and custom accelerators include specialized compute engines for matrix multiplication (also known as matmul or GEMM), such as NVIDIA’s Tensor Cores. These engines efficiently perform matmul on small tensor blocks; therefore, compilers or libraries typically divide large matmul problems into many smaller ones and feed them to these engines. Usually, the output from a Tensor Core of FP8 (e4m3) matmul with the shape of (block_size_m, block_size_k) and (block_size_k, block_size_n) is a (block_size_m, block_size_n) tensor in FP32 (e8m23). However, one interesting thing users rarely noticed is that for hardware efficiency reasons, this FP32 output could have fewer than 23 effective mantissa bits. In other words, the precision of this Tensor Core operation is lower than FP32 as it appears. This hardware design choice has been reported to impact model accuracy under certain circumstances 1, 2. Therefore, from a GPU user’s perspective, we would like to verify the hardware design in use. Because even though the existing hardware cannot be changed, custom kernels can still be written in a proper way to preserve highest achievable accuracy when needed. For hardware designers, it is equally important to have a convenient and efficient way to quantify the impact of this design choice.
Before we dive into details, we need to understand the role of an “accumulator” and the reason for employing reduced precision. Let’s first consider a hypothetical compute engine that can handle a FP8 matmul of block sizes (3, 4) and (4, 3), as illustrated in Fig. 1a. Zooming into the compute engine, the most basic operation would be a row-column inner product, i.e.
cᵢⱼ = ∑ₖ aᵢₖ * bₖⱼ. One can imagine that an efficient hardware design will simply implement 4 multipliers to compute each pair of aik, bkj, followed by 3 adders to sum up the intermediate results, as shown in Fig. 1b. In this simple example, we can see that the multiplication part can be done in one single parallelized “compute step” assuming enough multipliers are available. But the addition part requires 2 compute steps to complete, as it needs to be done in a hierarchical, serial way. If we scale up this unit design for N elements, multiplication will still take only one step while addition will take log(N) steps.
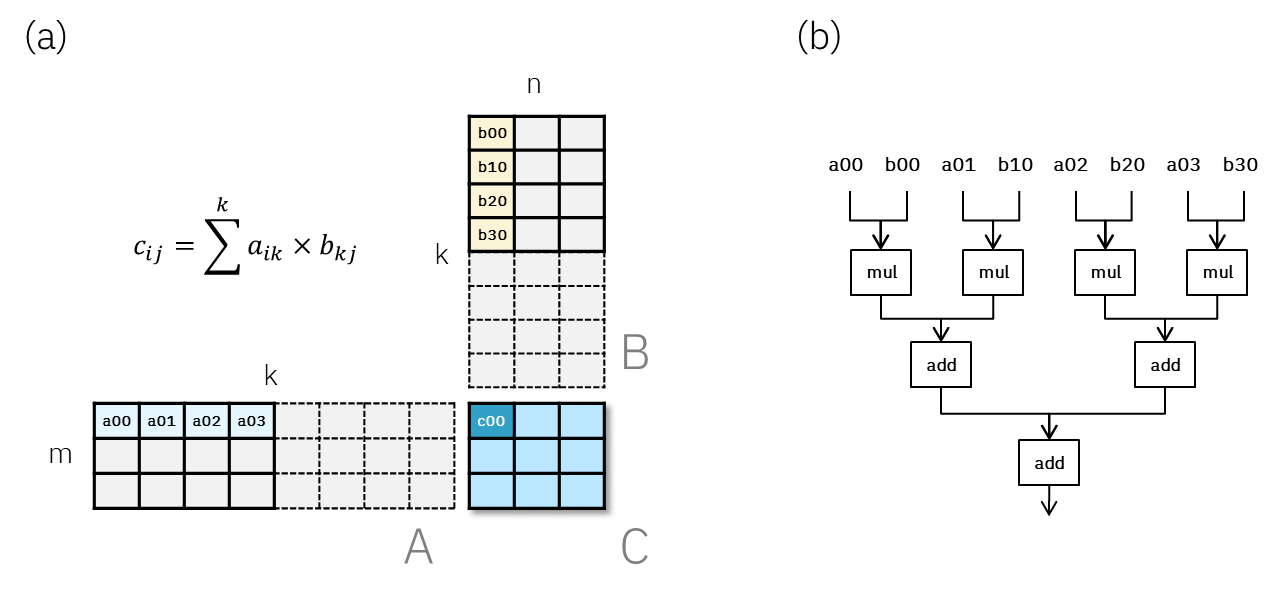
Furthermore, each multiplier only needs to compute FP8 * FP8 (e4m3), which involves a 4-bit + 4-bit addition (for exponent) and a 4-bit x 4-bit multiplication (for mantissa). However, since each partial product needs to be aligned correctly, the subsequent adders must use significantly more bits than the multipliers. As illustrated by Fig. 2 (just an example, not a real FP8 case), adding two limited precision FP numbers with only 4 mantissa bits could end up as a FP number that requires much more mantissa bits. This loosely explains why the circuit complexity and cost (silicon area and power) of a floating point multiply-accumulate (MAC) operation has a strong dependency on the accumulation precision. Therefore, even if it is safer to use FP32 as the accumulation precision (Fig. 2b), it is worthwhile to explore opportunities to use reduced accumulation precision.
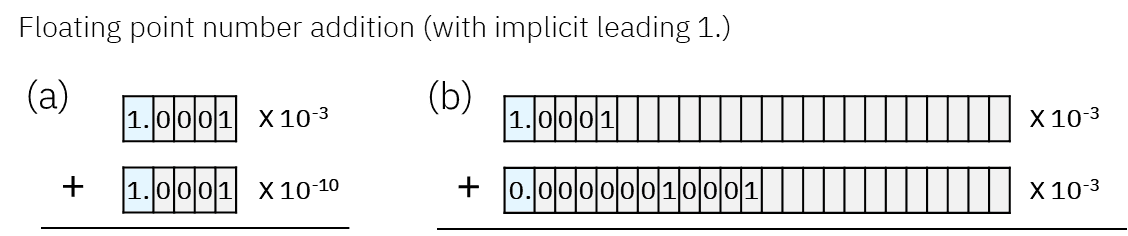
With these examples in mind, the benefits of using reduced‑precision adders in matmul engines become clear.
How to Verify Accumulator Precision? (Using TensorCore as an Example)
Given that a matmul accumulator could be designed with fewer than 23 mantissa bits, the actual output is effectively e8mNacc (where Nacc < 23) with trailing 0s padded up to e8m23. In other words, the output of FP8 TensorCore may look like FP32, but anything smaller than e8mNacc were never calculated during the computation. In this blog, we will demonstrate a simple approach to investigate the accumulator precision using triton kernel.
Assuming the TensorCore output has only Nacc effective mantissa bits (as in e8mNacc), i.e., the last 23 − Nacc bits are 0 already, if we apply a mask to truncate the last Ntrun bits of the TensorCore output, as long as Ntrun ≤ 23 − Nacc, the final matmul results should remain unchanged. Furthermore, by sweeping Ntrun and comparing the matmul output to a reference (i.e., Ntrun = 0), we can infer the accumulator precision of the FP matmul unit under investigation. Here, “truncation of Ntrun bits” refers to zeroing out the last Ntrun bits of a floating point number, which are the least-significant bits (LSBs) of the mantissa.
Why Triton?
We use triton language because it allows the proposed method to generalize to other accelerators that support Triton. It also greatly speeds up development for this experiment due to its simplicity and the right level of accelerator control. Although Triton is expected to evolve over time, because our implementation is based on Triton’s matmul tutorial, we anticipate the specific code requiring future rewrites will be minimal.
Experiments
A runnable code is provided at the end of this notebook. Here, we adopted a triton matmul kernel from triton tutorial and added a simple truncation function. Since a great amount of details can be found in the original tutorial, we will only highlight the truncation related modifications we made. Roughly speaking, matmul(A, B) is decomposed into smaller blocks and processed in parallel. Each block of A and B has shapes (BLOCK_SIZE_M, BLOCK_SIZE_K) and (BLOCK_SIZE_K, BLOCK_SIZE_N), respectively. The block-level matmul is computed by Triton’s tl.dot() function, producing a temporary tensor accumulator_inner of shape (BLOCK_SIZE_M, BLOCK_SIZE_N), which assumed to have only Nacc effective mantissa bits.
- Truncation of
accumulator_inner: We truncated the last Ntrun bits ofaccumulator_innerusing a bit operation with a pre-defined mask. For simplicity, we ignore rounding by settinground_bit= 0.
def prep_round_and_trun_mask(trun_bits): round_bit = 1 << (trun_bits - 1) if trun_bits > 0 else 0 trun_mask = ~tl.cast((1 << trun_bits) - 1, tl.uint32) return round_bit, trun_mask def round_and_trun(x, round_bit, trun_mask): """Round and truncate (usually for accumulator).""" return libdevice.uint_as_float( (libdevice.float_as_uint(x) + round_bit) & trun_mask )
2. Accumulation across the K-dimension: Each truncated accumulator_inner was further accumulated into a pre-allocated FP32 tensor accumulator while stepping through K-dimension. The shape of accumulator is the same as accumulator_inner.
3. Writing the results back: After iterating through the K-dimension, the final accumulator values are written back to the corresponding block in target output tensor C, whose shape is (M, N).
Results and discussions
From both Table 1 and Fig. 3 below, we observed that truncating up to 10 least significant mantissa bits of the output (using H100 FP8 TensorCore) produces exactly the same results as the case with no truncation. This indicates that those bits were already 0 in the original output. The experiment therefore suggests that the accumulator is implemented using a special FP22 format (e8m13) for compute efficiency reasons. We repeated this same experiment on an RTX4000-series GPU (Ada Lovelace architecture) and observed the same behavior.
One important consideration we should keep in mind is that this experiment relies on the Triton compiler to translate Triton codes into equivalent CUDA codes. We must ensure that the TensorCore performing the task is indeed the one we intended to inspect, i.e., FP8. In rare situations, the Triton compiler may choose to use FP16 TensorCore instructions for certain FP8 computations. The most reliable way to confirm the actual hardware instructions executed is to use the NVIDIA profiler ncu(3, which is included in cudatoolkit) to inspect the underlying CUDA instructions associated with the Triton tl.dot call.
Readers can save this notebook as a python file and then launch ncu using the following command-line invocation.
/usr/local/cuda-13.0/bin/ncu --target-processes all --set full --import-source yes -f --kernel-name matmul_kernel --launch-skip 3 --launch-count 1 -o ./tl_fp8mm_backend_H100 python accumulator_precision_test.py |
From ncu profiler readout shown below, we found that FP8xFP8 tl.dot() for the chosen block size (MxNxK=64x64x32) was translated into a QGMMA instruction — an FP8-TensorCore-specific instruction. This confirms that the FP8 TensorCore was indeed used.

As mentioned earlier, the Triton compiler can sometimes choose a different implementation for tl.dot. For example, if we set num_warps = 2 in kernel_config dictionary and repeat the experiment, Triton will pack FP8 into FP16 and use HMMA to perform the computation, where HMMA is a FP16-TensorCore-specific instruction. In this case, the corresponding results show that the accumulator of FP16 TensorCore is only 1 bit shorter than FP32.

Furthermore, since a specialized matmul unit is designed to handle inputs of certain fixed sizes, if BLOCK_SIZE we choose exceeds what TensorCore can handle, the compiler or CUDA library will automatically decompose the operation into several smaller operations. In our triton code, we can increase the BLOCK_SIZE K to 128 and verify with ncu again. We will see that each WGMMA instruction is only capable of dealing with K=32, which means there is an additional summation involved to combine the partial results from multiple TensorCore calls. A natural question is: What precision is used for this intermediate summation? This is the same FP alignment and precision loss problem that we have been discussing. Based on the output from K=128 experiment, we still observe 13 effective mantissa bits. This provides an important insight: if we choose block sizes for the triton kernel that exceed TensorCore’s base design, whether for performance reasons or due to autotuning, there can be additional precision loss from reduced precision summation. Therefore, if matmul precision is a critical concern (especially when training and backward propagation is involved), before falling back to FP16, we should first try to use an intermediate FP32 accumulation as we did in the triton codes. We demonstrated the BLOCK_SIZE_K effect on accuracy here but readers should keep in mind that smaller blocks will impact kernel performance. Readers may want to start from a larger block size, e.g. if autotuning suggests 256 or 512, then gradually reduce to 128, as used in 1, and consider the trade-off between using FP16 and decreasing block size. Alternatively, if using cuBLAS in the custom kernel, CUBLASLT_MATMUL_DESC_FAST_ACCUM flag can achieve the same effect of accumulation precision promotion. 4
Finally, the concept of a reduced-precision accumulator can also be applied to INT8xINT8 engines. The main difference between FP8 and INT8 matmul is that INT8 accumulator truncation occurs on the most significant bits (MSBs) rather than the least significant bits (LSBs). In other words, we need to consider overflow problem instead of underflow as in FP8. Simple modifications to the provided Triton kernel can be made to investigate INT8 behaviors. We leave this exercise to readers who are interested.
Conclusion
We explained the importance of using reduced precision in the accumulator of a matmul engine and demonstrated a simple method to verify the design of our existing accelerator. Understanding of accumulator precision is crucial for users with accuracy sensitive applications who write custom kernels, as well as for hardware designers who need to emulate this behavior for their next generation designs. More importantly, this triton-kernel-based approach can be seamlessly combined with the PyTorch ecosystem, which means the same technique can be extended to other existing and future accelerators that support the Triton language, significantly reducing development time.
Reference
- DeepSeek-V3 Technical Report, Section 3.3.2 Increasing Accumulation Precision. https://arxiv.org/html/2412.19437v1.
- SageAttention2, Introduction/Challenge/C2. https://arxiv.org/html/2411.10958v7
- ncu website https://docs.nvidia.com/nsight-compute/index.html
- https://docs.nvidia.com/cuda/cublas/
Runnable code can be found here
https://gist.github.com/chichun-charlie-liu/88a99949fcbe589aa5f71e48616ac944